
Surrogate Loss Functions and Fisher Consistency in Binary Classification
In the realm of binary classification, the ideal goal is to minimize the 0,1 loss, which simply assigns a penalty of 1 for every misclassified instance and 0 for a correct classification. Formally, if we denote the true label by and the prediction by , the 0,1 loss is defined as
In indicator notation, we can write this as
We often take , where is often referred to as an estimator or a decision function or the learned model or hypothesis that maps input features to a real-valued score, with its sign used to determine the predicted class label.
When and share the same sign, their product is positive (correct classification i.e. ), whereas if their product is non-positive (), it indicates a misclassification i.e. . Thus, defining , we penalize negative or zero , and the 0–1 loss can also be written as
Despite its intuitive appeal, directly minimizing this loss is computationally challenging because it is both discontinuous and nonconvex. This difficulty has led researchers and practitioners to adopt more tractable alternatives known as surrogate loss functions.
The Role of Surrogate Loss Functions
Surrogate losses are designed to approximate the 0,1 loss while offering the advantages of smoothness and convexity, properties that make optimization via gradient based methods feasible. Some of the most popular surrogate losses include:
- Hinge Loss: , famously used in Support Vector Machines.
- Exponential Loss: , which is the backbone of AdaBoost.
- Logistic Loss: , a staple in logistic regression.
- Truncated Quadratic Loss: , behaves quadratically up to a certain margin and then flattens out.
In these expressions, represents the margin, a product of the true label and the scoring function whose sign determines the classification.
Why Convexity Matters
Each surrogate loss is carefully chosen not only for its ease of optimization but also for its convexity. Convex functions are highly desirable in optimization because any local minimum is also a global minimum. Let us take a closer look at a few examples:
1. Hinge Loss
Defined as
the hinge loss is the pointwise maximum of the linear function and the constant function 0. We can break this down further:
Why Convex?-
Piecewise Definition:
For , we have , and for , . -
Convexity Criterion:
A function that is the maximum of two convex functions is itself convex. Here, the constant function 0 is convex, and is an affine (linear) function, which is convex. Thus, their pointwise maximum, , is convex. -
Conclusion:
Hence, is convex.
2. Exponential Loss
With the form
the exponential loss is smooth and strictly convex. The details are as follows:
- First Derivative:
- Second Derivative:
-
Positivity of Second Derivative:
Since for all real , it follows thatwhich implies that is strictly convex.
3. Logistic Loss
The logistic loss is given by
We now elaborate its mathematical properties:
-
First Derivative:
Let . Then,Hence,
-
Second Derivative:
Differentiating again,A systematic approach is to set (so that ) and apply the quotient rule. This yields:
-
Positivity of Second Derivative:
Since both and are positive for all , we have:confirming that is strictly convex.
It is important to note that although the standard logistic loss evaluates to at , which is below the value 1 of the 0,1 loss, this does not affect its minimizer. Both the standard logistic loss and its scaled version (where it is multiplied by so that it equals 1 at ) yield the same optimal decision boundary. The scaled version is used in theoretical analyses to ensure that the surrogate loss majorizes the 0,1 loss.
4. Truncated Quadratic Loss
Often defined as
this loss function is constructed by taking the maximum of a quadratic function and 0. This approach ensures that the penalty is quadratic for but does not grow unbounded for very confident predictions (i.e., when ). Since both and 0 are convex, their maximum is also convex.
Fisher Consistency, Bridging Surrogate Losses and the 0,1 Loss
One critical requirement for any surrogate loss is Fisher consistency. A surrogate loss is Fisher consistent if minimizing the expected surrogate risk leads to the same decision boundary as minimizing the 0,1 loss in the limit of infinite data.
Consider the conditional probability . The Bayes optimal classifier under the 0,1 loss is given by
When we define the surrogate risk as
Fisher consistency requires that the function which minimizes also satisfies
Thus, even though we are not minimizing the 0,1 loss directly, the surrogate risk leads us to the optimal classification rule as the amount of data grows.
Surrogate Losses as Upper Bounds
Surrogate loss functions are used not only because they are easier to optimize than the 0,1 loss but also because they provide an upper bound on the 0,1 loss. Recall that the 0,1 loss is defined as
and the surrogate risk for a classifier is given by
where is a convex surrogate loss function for the 0–1 loss.
Classification Calibration:
A surrogate loss is classification calibrated if there exists a function such that for any measurable function ,
where
is the misclassification error, is the Bayes risk (i.e. the minimum possible misclassification error), and is the surrogate risk.
To express this pointwise, define the conditional risk at for the surrogate loss as
with . A surrogate loss is classification calibrated if, for every with , any minimizer of the conditional risk
satisfies
Here’s how this ensures that lowering the surrogate risk will lead to lower misclassification error:
The inequality
tells us that if a classifier’s overall misclassification error is at least worse than the best achievable (Bayes risk), then its overall surrogate risk must be at least worse than the optimal surrogate risk. Since is strictly positive for any , there is a quantifiable gap in surrogate risk whenever there is a gap in misclassification error. In practical terms, if you manage to reduce the surrogate risk (i.e. make closer to ), then the corresponding misclassification error gap must also decrease; otherwise, the surrogate risk gap would remain above the threshold given by .
Therefore, Fisher consistency focuses on the theoretical, ideal alignment between the surrogate risk minimizer and the Bayes optimal decision rule (i.e. in the conditional risk sense, ensuring that for each , the best decision under the surrogate loss agrees with ). In contrast, classification calibration provides a practical guarantee: it ensures that reducing the overall surrogate risk will directly lead to a reduction in the overall misclassification error. Thus, while both properties ensure that the surrogate loss guides us toward the Bayes optimal classifier, classification calibration explicitly links improvements in the surrogate risk with improved classification performance.
Below, we demonstrate this mathematically for the hinge loss.
Mathematical Demonstration for Hinge Loss
The hinge loss is defined as
which can be written in piecewise form as
For a fixed , define the conditional risk associated with a surrogate loss as
where and .
For the hinge loss, assume so that:
- (since ), and
- (since when ).
Then the conditional risk becomes:
Now, analyze the behavior of :
- If , then , so is a decreasing function of . Its minimum over is achieved at .
- If , then , so is an increasing function of . Its minimum is achieved at .
- If , then for any , meaning any minimizes the risk.
Thus, the minimizer is:
Taking the sign, we obtain:
which is exactly the Bayes optimal decision rule under the 0,1 loss. Therefore, minimizing the hinge loss is Fisher consistent.
Mathematical Demonstration for Logistic Loss
The logistic loss is defined as
For a fixed , define the conditional risk associated with a surrogate loss as
where and .
For the logistic loss, this becomes
To find the minimizer , differentiate with respect to and set the derivative equal to zero.
-
Differentiate the first term:
The derivative of with respect to is -
Differentiate the second term:
Similarly, the derivative of with respect to is
Thus, the derivative of the conditional risk is
Setting , we obtain
With some algebraic manipulation (multiplying numerator and denominator appropriately or recognizing standard forms), one can show that the solution to this equation is
Now, observe the sign of :
- If , then , so .
- If , then , so .
- If , then .
Thus,
which is exactly the Bayes optimal decision rule under the 0,1 loss.
Therefore, minimizing the logistic loss is Fisher consistent, because it leads to the same decision boundary as minimizing the 0,1 loss.
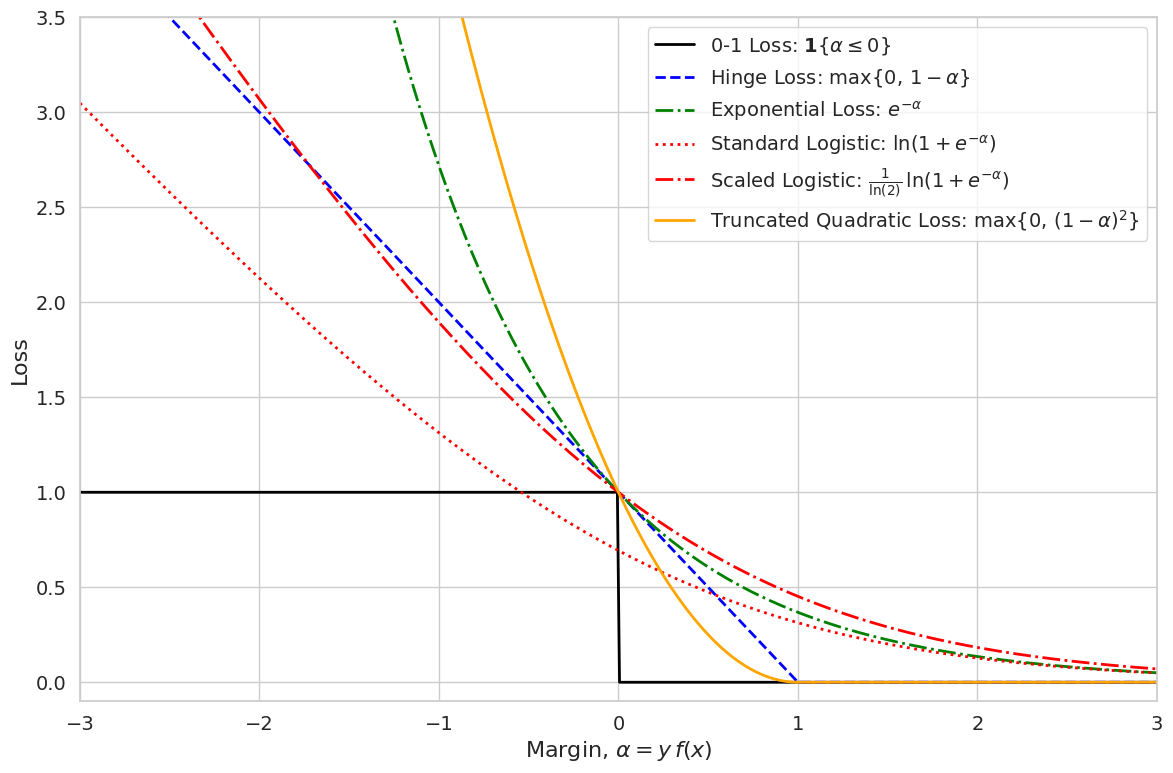
Visual Interpretation
Refer to the plot above where the 0,1 loss is depicted as a step function that jumps from 0 to 1 at . Overlaying this step function, the following surrogate curves are displayed:
- Hinge Loss: Defined as , this piecewise linear curve increases linearly for and is 0 for . It is favored for its simplicity and the ease with which it can be optimized.
- Exponential Loss: Given by , this smooth curve decays exponentially as increases, thereby penalizing misclassified examples with a low margin quite heavily.
- Standard Logistic Loss: This is expressed as . Note that at , it evaluates to , which lies below the 0,1 loss value of 1. However, despite this pointwise difference, both the standard logistic loss and any suitably scaled version yield the same minimizer due to the property of classification calibration.
- Scaled Logistic (Deviance): To obtain a curve that majorizes the 0,1 loss, the logistic loss is often scaled by a factor of . This scaled version, attains the value 1 at and lies entirely above the 0,1 loss for . The scaling does not change the minimizer of the surrogate risk but is useful for theoretical guarantees that the surrogate risk upper bounds the misclassification error ( ).
- Truncated Quadratic Loss: Defined as for and 0 for , this loss combines a quadratic penalty with a truncation to avoid excessive punishment for high-margin points.
The key point is that although the standard logistic loss may be below the 0,1 loss at , its classification-calibrated property ensures that minimizing its risk leads to the same optimal classifier as minimizing the 0,1 loss. In contrast, the scaled logistic loss (or deviance) is adjusted to lie above the 0,1 loss, making it a strict upper bound in that region. This property is crucial for deriving theoretical risk bounds and for ensuring that the surrogate risk is a faithful proxy for the true misclassification error.
Key Takeaways:
- 0,1 Loss and Its Challenges: The 0,1 loss is the most natural measure of misclassification but is nonconvex and discontinuous, making it computationally intractable for direct optimization.
- Surrogate Loss Functions: Surrogates such as hinge, exponential, logistic, and truncated quadratic losses offer smooth and convex approximations that greatly simplify the optimization process. Their forms can be further adjusted, for example by scaling, to ensure they majorize the 0,1 loss.
- Fisher Consistency: A key property of these surrogate losses is classification calibration. This means that even if the surrogate’s pointwise values differ from the 0,1 loss (as seen with the standard logistic loss), minimizing the surrogate risk ultimately yields the same decision boundary as minimizing the 0,1 loss.
- Upper Bound Nature: By appropriately scaling (e.g., multiplying the logistic loss by ), surrogate losses can be made to serve as strict upper bounds on the 0,1 loss. This theoretical guarantee is critical for deriving risk bounds and ensuring that optimizing the surrogate risk indirectly minimizes the true classification error.
- Optimization and Theoretical Guarantees: The convexity of these surrogate losses not only enables efficient gradient-based optimization but also provides robust theoretical guarantees that the surrogate risk is closely aligned with the true misclassification risk.
Surrogate loss functions play a pivotal role in modern machine learning by bridging the gap between computational tractability and statistical optimality. While the 0,1 loss is the most intuitive measure of classification error, its nonconvex and discontinuous nature renders it impractical for optimization. In contrast, surrogate losses—such as the hinge, exponential, logistic, and truncated quadratic losses—provide smooth and convex alternatives that are far easier to minimize. Importantly, these surrogates are designed to be Fisher consistent; that is, they ensure that minimizing the surrogate risk yields the same optimal decision boundary as the 0,1 loss in the infinite-sample limit. Moreover, by scaling losses like the logistic loss (resulting in the deviance), we can enforce that the surrogate not only approximates but strictly upper-bounds the 0,1 loss in the region of interest. This property is crucial for both practical algorithm performance and the derivation of rigorous theoretical risk bounds. Ultimately, the careful selection and scaling of surrogate losses enable practitioners to harness the power of convex optimization while accurately approximating the ultimate goal of minimizing misclassification error.