
Bayesian Linear Regression
Bayesian Linear Regression: Fundamentals, Ridge, and Lasso Regularization
Bayesian linear regression provides a probabilistic framework for modeling the relationship between predictors and a response variable. In this framework, model parameters are treated as random variables, and we derive a full posterior distribution for them rather than just point estimates. In the sections below, we first detail the standard Bayesian linear regression model and then extend the discussion to two popular regularization methods: Bayesian Ridge and Bayesian Lasso.
Key Bayesian Regression Framework
Model Setup and Notation
We begin with the familiar linear model:
where:
- is an response vector,
- is an design matrix (including a column for the intercept),
- is a vector of unknown coefficients, and
- the errors are assumed to be independent and normally distributed as
Standard Bayesian Linear Regression
Likelihood
In the Bayesian framework, we combine the data likelihood with a prior distribution on the parameters. In statistical modeling, the likelihood function represents the probability of observing the data given the parameters and . For our linear model, with independent normally distributed errors, the likelihood function is given by:
where is the th row of . This can be simplified as:
Prior
In the Bayesian setting, we treat as a random variable. A common (noninformative or weakly informative) choice is to assume a Gaussian prior on , which is conjugate to the Gaussian likelihood. This leads to analytic solutions and simplifies computation:
where controls the spread or uncertainty of our prior relative to the noise variance .
However, the Gaussian prior is not the only choice. Depending on the application and prior beliefs, different priors can be used:
-
Noninformative Prior: When little prior knowledge is available, one might use a flat or uniform prior over i.e. . This approach does not favor any particular values and lets the data speak for itself.
-
Weakly Informative Gaussian Prior: In many cases, a Gaussian prior with a large variance (small ) is used to provide mild regularization without imposing strong beliefs. This is particularly useful for stabilizing estimates in the presence of multicollinearity.
-
Laplace Prior (Double-Exponential): For scenarios where sparsity is desired, such as in variable selection, a Laplace prior can be imposed on each coefficient. This is the basis for the Bayesian Lasso:
-
Heavy-Tailed Priors: In some applications, it might be appropriate to use heavy-tailed distributions like the Student's t-distribution as a prior for . Such priors are more robust to outliers in the data and allow for occasional large coefficient values.
The choice of prior should reflect any prior knowledge or assumptions about the parameters. For example, if prior studies suggest that most predictors have a negligible effect on the response, a Laplace prior might be preferred to encourage sparsity. Conversely, if one has reason to believe that the effects are normally distributed around zero with moderate variance, a Gaussian prior is appropriate.
Posterior: Combine Likelihood and the Prior
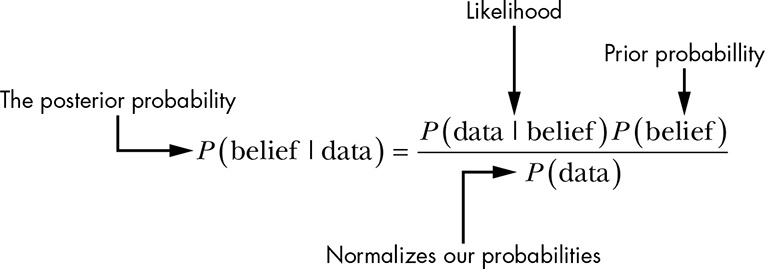
Bayesian inference uses Bayes’ rule in the form:
Next, we write the marginal likelihood by integrating over all possible :
However, computing (the marginal likelihood) can be challenging because it involves integrating over all possible parameter values. That is why we often write the posterior up to a proportionality constant. The posterior distribution for is proportional to the product of the likelihood and the prior:
Therefore, for our setup the posterior distribution is:
Because both the likelihood and the prior are Gaussian, the posterior for is also Gaussian. This conjugacy yields an analytic solution for the posterior, allowing us to quantify the uncertainty over the coefficients.
Posterior Distributions: Analytic and Approximate Forms
The posterior distribution arises when we update our beliefs about parameters after observing data, capturing both our prior assumptions and the information contained in the likelihood. In some situations—especially when the chosen prior and likelihood form a convenient pairing—the necessary integrals can simplify, leading to an exact, closed-form expression for the posterior.
In certain cases, the likelihood and prior are chosen to be conjugate. This means the resulting posterior has the same functional form as the prior, making it possible to derive a closed-form (analytic) solution easily. These so-called "conjugate" relationships are not the only way to obtain analytic solutions, but in most practical cases, the marginal likelihood integrals become too complex to solve directly.
Non-Analytic Example: Bayesian Logistic Regression
- Model Setup
-
Likelihood
Suppose are binary outcomes and is the design matrix. For logistic regression, each is modeled with
where is the logistic function. The likelihood for all data points is:
-
Prior
We can again choose a Gaussian prior for :
- Posterior Challenge
-
Form of the Posterior
Using Bayes’ rule, the posterior is:
The presence of the logistic function in the product creates a non-conjugate relationship with the Gaussian prior.
-
No Closed-Form Integral
Unlike the Gaussian–Gaussian case, the integral
does not simplify into any known closed-form solution. This makes the posterior analytically intractable.
As a result, we often rely on numerical approaches such as Markov Chain Monte Carlo (MCMC), variational inference, or other approximation methods to explore or estimate the posterior distribution. These techniques ensure that even when an exact solution is not feasible, we can still capture the uncertainty about our parameters and make informed inferences from the data.
By working with a full posterior distribution, Bayesian linear regression enables the incorporation of prior information and provides a way to capture uncertainty. Instead of a single point estimate for each , you get a distribution reflecting all plausible values and their corresponding probabilities.
Bayesian Ridge Regression
In Bayesian Ridge Regression, we use the same Gaussian prior:
Likelihood:
The likelihood function remains:
Prior:
The Gaussian prior on the coefficients is:
Posterior:
By Bayes’ rule, the posterior is:
Taking the negative logarithm (and ignoring constants) gives the following objective for Maximum A Posteriori (MAP) estimation:
Multiplying through by (which does not affect the minimizer) leads to:
Derivation of the MAP Estimate:
Taking the derivative with respect to and setting it to zero:
Rearrange to obtain:
Thus, the MAP estimate for Bayesian Ridge Regression is:
Bayesian Lasso Regression
Bayesian Lasso introduces sparsity by using a Laplace (double-exponential) prior on the regression coefficients.
Model, Likelihood, and Prior for Bayesian Lasso
Model:
We retain the linear model:
Likelihood:
The likelihood function is:
Prior:
For Bayesian Lasso, we place a Laplace prior on each coefficient :
For the entire coefficient vector:
Posterior and MAP Estimation for Bayesian Lasso
Posterior:
Using Bayes’ rule, the posterior distribution is given by:
Taking the negative logarithm (ignoring constants) yields the MAP objective:
Multiplying through by for clarity, we have:
Note:
Due to the non-differentiability of the norm at zero, there is no closed-form solution for the Bayesian Lasso MAP estimator. In practice, numerical methods such as Gibbs sampling, variational inference, or coordinate descent adapted for the Bayesian framework are used to estimate or to sample from the full posterior.
Hyperparameter Interpretation
An important aspect of Bayesian linear regression is understanding the role of the hyperparameters. The parameter in the Gaussian prior (used in standard Bayesian regression and Bayesian Ridge) controls the spread of the prior distribution on ; a larger implies a tighter prior (i.e., more shrinkage), while a smaller allows for greater variability in the coefficient estimates. Similarly, in Bayesian Lasso, the hyperparameter governs the strength of the penalty, where a larger encourages more coefficients to be shrunk to exactly zero, thereby promoting sparsity and enhancing variable selection. Tuning these hyperparameters is critical, as they directly affect the balance between model complexity and regularization, ultimately influencing both the predictive performance and interpretability of the model.
Summary of Bayesian Linear Regression Methods
-
Standard Bayesian Linear Regression:
- Model:
- Notation:
is an response vector, is an design matrix, is a coefficient vector. - Prior:
. - Posterior:
, leading to a closed-form MAP solution akin to ridge regression.
-
Bayesian Ridge Regression:
- Prior:
. - MAP Estimator:
- Benefits:
Provides shrinkage of coefficients and quantifies uncertainty via the full posterior distribution.
- Prior:
-
Bayesian Lasso Regression:
- Prior:
Laplace prior . - MAP Objective:
- Benefits:
Encourages sparsity by driving some coefficients to exactly zero, aiding in variable selection. No closed-form solution exists; numerical methods are employed.
- Prior:
Practical Considerations
In practice, Bayesian linear regression models are often implemented using computational techniques such as Markov Chain Monte Carlo (MCMC) methods, including Gibbs sampling or the Metropolis-Hastings algorithm, to sample from the posterior distribution. Software packages such as Stan, JAGS, or PyMC3 provide powerful tools for performing these computations, enabling the estimation of complex Bayesian models. However, practitioners should be aware of the computational challenges associated with MCMC, such as convergence diagnostics and potential slow mixing in high-dimensional parameter spaces. Variational inference is another alternative that approximates the posterior more quickly, although sometimes at the cost of reduced accuracy. These practical considerations are crucial when applying Bayesian methods to real-world datasets.
Bayesian linear regression not only yields point estimates for the coefficients but also provides a full probabilistic description of uncertainty. By incorporating regularization through Bayesian Ridge and Bayesian Lasso, we obtain models that are robust to overfitting and multicollinearity, while also offering valuable insights through the posterior distributions.
Further Reading & Citations
- Gelman, A., Carlin, J. B., Stern, H. S., Dunson, D. B., Vehtari, A., & Rubin, D. B. (2013). Bayesian Data Analysis. Chapman & Hall/CRC.
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Park, T., & Casella, G. (2008). The Bayesian Lasso. Journal of the American Statistical Association, 103(482), 681-686.